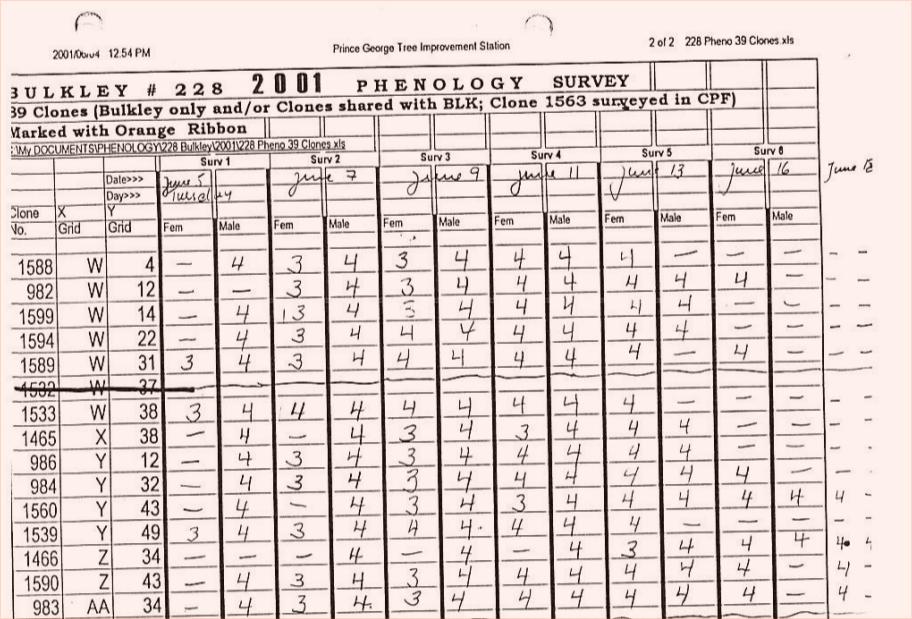
Sample of my data courtesy of Rita Wagner at the Prince George Tree Improvement Station
My research depends on data that many, many people have collected over many, many years. A lot of it is still on data collection sheets used in the field and has been sitting ignored in filing cabinets. It is absolutely fantastic that people have been willing to dig up and share this stuff with me. Hopefully by the end of my project I’ll have a great big data package to publish on dryad! Then whenever anyone needs this kind of data, no one has to waste time digging through decades of old files.
Now that I’ve got the data, I need to analyze it. And to do that I need to get these handwritten data into something I can feed R. Before I talk some poor undergrad into helping me out, I thought I’d look into some kind of automated solution. My knowledge of OCR at this point is “sometimes some program can read text in an image.” Any advice? You can see a sample of what I’m working with in the image above.
RT @scisus: One hundred and fifty pages of data – #OCR help http://t.co/xa0IADvr
@scisus I know a bit about handwritten OCR *methods*, but I’m afraid that’s it. I’ve re-tweeted for you, in case someone knows more.
@scisus Handwritten digit recognition is well-studied. The hardest part might be overflow columns etc.
[…] month I asked for advice on automating a huge bunch of data transcription. At that point, my knowledge of OCR was […]